
Don't you want to read? Try listening to the article in audio mode 🎧
Data Scraping ist die Bezeichnung für ein Feld, das unterschiedliche Bereiche umfasst. Dazu gehören die Optimierung der Inhalte für Suchmaschinen oder auch Marktanalysen, die Erstellung von Vertriebsstrategien und Cyber Security. Versuchen wir also zu die unterschiedlichen Techniken zu verstehen und auch die Bereiche, in welchen sie zur Aufwertung der Daten genutzt werden können.
 Im Wesentlichen handelt es sich um eine Lösung für Data Mining, die die Onlinesuche vereinfacht und mit XPath kompatibel ist. Auf diese Weise haben die Entwickler die Möglichkeit, eigens für die Interaktion mit den gesammelten Informationen konzipierte Scripts zu erstellen.
Im Wesentlichen handelt es sich um eine Lösung für Data Mining, die die Onlinesuche vereinfacht und mit XPath kompatibel ist. Auf diese Weise haben die Entwickler die Möglichkeit, eigens für die Interaktion mit den gesammelten Informationen konzipierte Scripts zu erstellen.
Scraping: Was es ist
Im weitesten Sinne ist Data Scraping ein Prozess, bei dem eine Applikation Daten aus dem Output einer anderen Software extrahiert. Im spezifischen Fall des Internets besteht Scraping darin, Daten von einer Website abzuschöpfen, diese auf Basis ihrer Eigenschaften zu klassifizieren, sie in Kategorien zu unterteilen und dann innerhalb einer Datenbank zu archivieren. Ein Beispiel für Scraping kann man anhand von Suchmaschinen verdeutlichen. Plattformen wie Google scannen das Internet unentwegt mit Crawler (auch “Spider”) genannten Softwares, die ganz automatisch an der Erkennung und Analyse der Inhalte arbeiten. Die Suchen der Nutzer werden auf der Grundlage von Textketten formuliert, die Schlüsselwörter enthalten. Da es das Ziel von Google ist, möglichst genaue Antworten auf diese Suchanfragen (oder “Query”) zu geben, extrahiert sein Crawler Texte oder Teile von Texten aus den Websites, um nützliche Daten für Ergebnisvorschläge zu erhalten. Die Ergebnisse werden durch die SERP (“Search Engine Results Page”) dargestellt und auf Basis verschiedener Kriterien positioniert. Dazu gehört zum Beispiel die Relevanz, die Qualität bezüglich der Nutzererfahrung und die Maßgeblichkeit der Quelle, mit der die durch Scraping erhaltenen Daten aufgewertet werden.Ungesetzliche Nutzung von Scraping
Scraping ist nicht immer eine gesetzeskonforme Aktivität, man muss nur an den Abzug von Daten zum Zweck des unerlaubten Kopierens von Inhalten denken. In solchen Situationen kann es schnell zur Verletzung von Urheberrechten kommen, vor allem wenn der Autor nicht korrekt genannt wird und/oder sein Werk in Teilen oder vollständig zu wiedergegeben oder widerrechtlich verkauft wird. Darüber hinaus kann Scraping leider auch kriminelle Aktivitäten unterstützen. Beispielsweise bei Phishingkampagnen, Identitätsdiebstahl und anderen Cyberattacken kommt Scraping zum Einsatz. Aus diesem Grund standen in der Vergangenheit Netzwerke wie Facebook und LinkedIn, die von einem Großteil der Weltbevölkerung genutzt werden, im Zentrum von Scrapingaktivitäten. Die Daten von Millionen Nutzern und Nutzerinnen wurden skrupellos abgeschöpft. Dies ist umso besorgniserregender, da es für das Scraping einer Website noch nicht einmal nötig ist, in die Datenbank einzudringen, sondern es ausreicht, die öffentlich zugänglichen Seiten zu scannen. Die zum Scraping nötigen Softwares werden außerdem nicht als illegal angesehen, sondern können von jeder Person legal zur Datenanalyse verwendet werden. Hierbei ist es aber wichtig festzuhalten, dass die GDPR, d.h. die Allgemeine Datenschutzverordnung der Europäischen Union, auch nur den Zugriff auf persönliche Daten als “Verarbeitung” derselben ansieht und die Techniken des Scraping deshalb nur unter Berücksichtigung aller geltenden Datenschutzbestimmungen angewendet werden dürfen.Scraping zur Datenanalyse
Scraping ist aus seiner Anlage heraus ein datengetriebener Prozess. So sind es auch die Unternehmen, die es zur Bestimmung ihrer Marketing- und Vertriebsstrategie verwenden. Aber welche sind die Bereiche, in denen die Techniken des Scrapings am meisten Erfolg versprechen? Im Folgenden werden wir einige davon analysieren.Textanalyse und Extraktion von Keywords
Der Erfolg von online veröffentlichten Inhalten wird von verschiedenen Faktoren bestimmt, darunter wie viel Verkehr sie zu erzeugen in der Lage sind und ihre Verbindung zu aktuellen Trends. Unter diesem Gesichtspunkt kann eine kontinuierliche Analyse der Angebote anderer Content Creator sowie der Konkurrenz nützlich sein. Ein solcher Prozess kann sich jedoch als sehr arbeitsreich und mühsam erweisen, wenn er manuell durchgeführt werden muss. Deshalb ist das Data Scraping so wertvoll. Ähnliches lässt sich für die Kampagnen im digitalen Marketing sagen, die häufig die Grundlage für die bereits erwähnte Produktion von Inhalten darstellen. Damit diese erfolgreich sein können, ist es nützlich zu wissen, welche Inhalte besonders gut angenommen, von den Nutzern und Nutzerinnen am häufigsten gesucht werden und so einen Trend begründen. Zur Maximierung der Wettbewerbsfähigkeit ist es deshalb unerlässlich, die wirksamsten Keywords zu ermitteln und gleichzeitig neue mit maximalem Wachstumspotenzial zu finden. Folglich verwendet man Scraping, um auf verschiedenen Plattformen veröffentlichte Texte oder Hashtags zu extrahieren, sie in Kategorien zusammenzustellen und sie dem Prozess der Keyword Extraction zu unterziehen. So kann man Schlüsselwörter herausfinden, welche dann in die eigenen Inhalte sowie Werbekampagnen eingefügt werden können.Preisanalyse
Ein weiterer Bereich, in dem Scraping bei Unternehmensentscheidungen oft eine Rolle spielt, betrifft die Entwicklung der Preise. Vor allem für Unternehmen, die sehr wettbewerbsintensive Produkte verkaufen, ist es wichtig zu wissen, ob die berechneten Preise konkurrenzfähig sind oder ob sie angepasst werden müssen. Nur so ist es möglich, das richtige Gleichgewicht zwischen Vergütung und Marktparametern zu garantieren. In diesem Fall wird Scraping dazu verwendet, eine bestimmte Angabe zu ermitteln. Das Ziel ist, eine stets aktuelle Datenbank zu erstellen, mit welcher man Vergleichsanalysen durchführen und auf die man sich bei der Bestimmung der Preisstrategie jederzeit beziehen kann. Diese Art von Aktivität erweist sich auch als sehr nützlich bei der Erstellung von Rabatten, Sonderaktionen und Angeboten, oder auch in Zeiten, in denen die Kaufneigung verstärkt vorhanden ist wie beim Black Friday, Cyber Monday oder allgemein in der Vorweihnachtszeit.Einige nützliche Scraping-Tools
Dank der Verfügbarkeit einiger no-code Instrumente ist Scraping heutzutage zu einer einfachen Prozedur geworden, die keine fortgeschrittenen Programmierkenntnisse erfordert. Die Grundlage der Scraping-Technologien bildet ein Standard mit dem Namen XPath. Dieser ist praktisch eine Sprache aus der Familie der XML (eXtensible Markup Language), die es erlaubt, die Knoten eines Dokuments festzustellen oder, besser gesagt, zu lokalisieren. Dies ermöglicht es, Ausdrücke zu schreiben, mit denen man direkt auf spezifische Elemente einer HTML-Seite wie beispielsweise eine Website Zugriff hat und ist so ideal für die Extraktion von Texten. Es existieren verschiedene Tools, mit denen man Scraping durchführen kann, ohne dass man XPath-Ausdrücke schreiben muss oder die diese (wenn nötig) integrieren lässt. Hier die Analyse einiger:Google Sheets
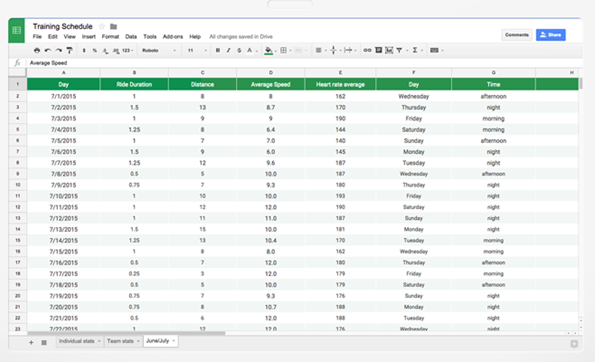
Google Sheets ist ein in Mountain View entwickeltes Instrument, mit dem sich Arbeitsblätter entwickeln und abändern lassen. Im Fall von Scraping bietet es eine seiner wichtigsten Funktionalitäten durch IMPORTXML an.
fonte.(google.com)
Diese erlaubt es, Informationen aus verschiedenen Formaten für strukturierte Daten wie beispielsweise XML, HTML, CSV, RSS und ATOM zu importieren. Dadurch bietet sich die Möglichkeit, bei der Verwendung von Google Sheets Daten direkt von Websites zu importieren und sofort verwendbare Tabellen herzustellen, bei denen man online abgeschöpfte Inhalte als Quelle benutzt.Scraper
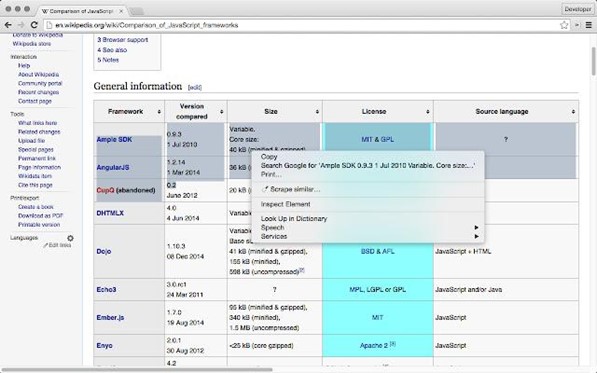
Scraper ist eine kostenlose Erweiterung des Webbrowsers Google Chrome, mit der es möglich ist, bestimmte Teile einer Website zu extrahieren. Die auf diese Weise gewonnenen Daten können zur nachfolgenden Analyse in ein Arbeitsblatt eingefügt werden.
Im Wesentlichen handelt es sich um eine Lösung für Data Mining, die die Onlinesuche vereinfacht und mit XPath kompatibel ist. Auf diese Weise haben die Entwickler die Möglichkeit, eigens für die Interaktion mit den gesammelten Informationen konzipierte Scripts zu erstellen.
Screaming Frog
Screaming Frog ist ein besonders für das Webscraping mit Ausrichtung auf SEO (Search Engine Optimization) geeignetes Tool. Die Plattform bietet nämlich ein SEO Spider Tool zur Datenextraktion von Websites an.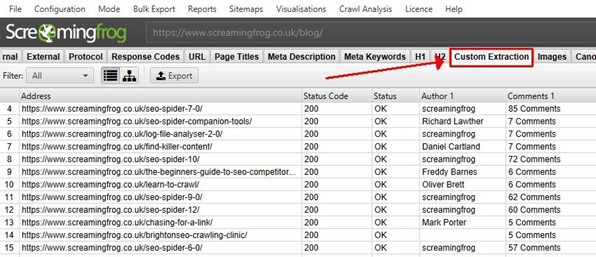
fonte:(screamingfrog.co.uk)
Die Nutzererfahrung lässt sich in der Variante CSSPath, die die Verwendung von Selektoren CSS (Cascading Style Sheets) zur Feststellung der Daten erlaubt und regelmäßige Ausdrücke verwendet, um Suchmuster zu bestimmen, über XPath-Ausdrücke personalisieren.Abschließend
Scraping ermöglicht es, Daten von Outputs aus Applikationen und Websites durch Tools und automatisierte Prozess zu extrahieren. Seine Rolle bei der Datenanalyse wird immer wichtiger. Es wird einem ermöglicht, auf Informationen zuzugreifen, die für digitales Marketing, SEO, Preisstrategie, datengetriebene Businessabläufe und Unternehmensentscheidungen extrem wertvoll sind.
Artikel aktualisiert am: 09 August 2023
Lesen Sie weiter

Data Science für Unternehmen: Wie kann man Data Science optimal nutzen?
Viele Unternehmen bauen ihre Aktivitäten auf dem Sammeln von Daten mit Hilfe moderner Technologien auf, die die ...
11/05/2021

Was NFT sind und wie sie funktionieren
NFT ist das Akronym für “Non-Fungible-Token” und bezeichnet die im Moment neben Kryptowährungen populärsten digitalen ...
08/03/2022

Was ein Data Engineer macht, wie man zu einem wird und wie viel man durchschnittlich verdient
Um das Berufsbild des Data Engineer zu beschreiben, beginnt man am besten mit einem Bezug zuBig Data. Damit ist die ...
23/05/2022

Was machen Performance Marketing Specialists, wie wird man es und welche sind die Verdienstmöglichkeiten
Onlinewerbung nimmt mittlerweile eine fundamentale Rolle beim Aufbau eines Markenimages, der Werbung für Produkte und ...
24/05/2022
